![]() Project Gutenberg offers over 40,000 free ebooks: choose among free EPUB books, free kindle books, download them or read them online. Recently, they have added support for Dropbox, so you can download ebooks directly to your Dropbox account. It will create a folder ‘Apps/gutenberg’, and will store all ebooks in that folder.
Project Gutenberg offers over 40,000 free ebooks: choose among free EPUB books, free kindle books, download them or read them online. Recently, they have added support for Dropbox, so you can download ebooks directly to your Dropbox account. It will create a folder ‘Apps/gutenberg’, and will store all ebooks in that folder.
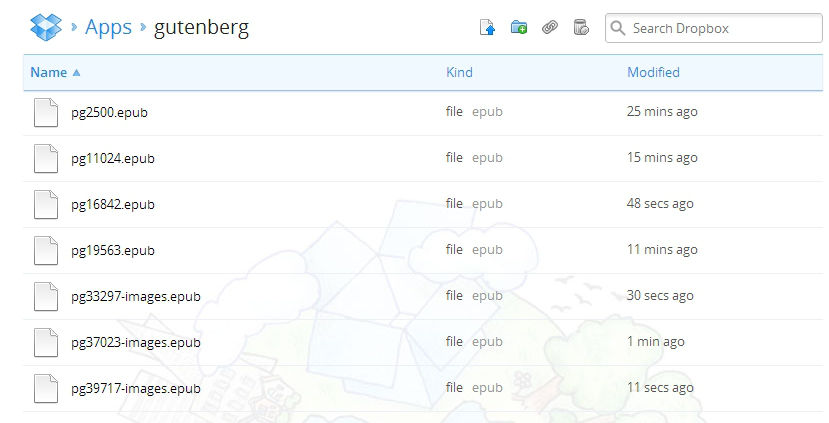
After a while, this Dropbox folder will have a long list of files, all with names like pg1234.epub and pg5678-images.epub. They have some meaning, but which file contains which title? Of course, you can rename each ebook after downloading, but this is extra work, and I want a smart solution.
So I created a script to create an index for all ebooks–at least, for those in EPUB format. Now there is simply an index.html file, which will open in any browser. It shows the file name, together with the creator, title and language. Depending on how you view the index.html file, the links may be clickable, In any case, you can quickly see which file is which book.

The script works on any set of EPUB file, but usually, they will have a more meaningful name and there will be less need for a script like this.
The concept is simple:
- Check all files in a folder
- For EPUB files, read the metadata and keep that information
- Present the information in a readable (HTML) format
The hardest part is reading the EPUB files. You can find more information on the EPUB format on WIkipedia. In this context, it is important to know that an EPUB file is a ZIP archive, it contains a file META-INF/container.xml, which points to an OPF file with information about the publication.
I have chosen to create a script in PHP, as PHP has many libraries, and can handle both ZIP and XML files using these libraries. PHP can be installed on many platforms; it is often used for web pages, but here we only need to run it from the command line.
So there we go:
<?php
// Structure in which the index will be build
$index = array();
// The fields that will be extracted
$fields = array( 'creator', 'title', 'language' );
// Instances of required classes
$zip = new ZipArchive;
$xml = new DOMDocument;
// Get files in folder
$files = scandir( '.' );
foreach( $files as $file ) {
// Index .epub files only
if( preg_match( '/\.epub$/', $file )) {
if ($zip->open( $file ) == TRUE) {
Looping through the files, I use a regular expression to select the EPUB files, and proceed if I can open it as a ZIP file:
// load container.xml in xml structure
if( $xml->loadXML( $zip->getFromName( 'META-INF/container.xml' ))) {
The container.xml file is now loaded in the DOMDocument $xml. It looks like this:
<?xml version='1.0' encoding='utf-8'?> <container xmlns="urn:oasis:names:tc:opendocument:xmlns:container" version="1.0"> <rootfiles> <rootfile media-type="application/oebps-package+xml" full-path="2500/content.opf"/> </rootfiles> </container>
The OPF file can be found using the full-path attribute of the rootfile tag.
// Get full-path attribute of rootfile tag $path = $xml->getElementsByTagName( 'rootfile')->item(0)->getAttribute( 'full-path' );
That’s all we need from this XML file, so we can use the instance now to load the OPF file, which is also in XML format.
if( $xml->loadXML( $zip->getFromName( $path ))) {
This OPF file looks like below (this is only part of the file)
<metadata> <dc:rights>Public domain in the USA.</dc:rights> <dc:identifier id="id" opf:scheme="URI">http://www.gutenberg.org/ebooks/2500</dc:identifier> <dc:creator opf:file-as="Hesse, Hermann">Hermann Hesse</dc:creator> <dc:title>Siddhartha</dc:title> <dc:language xsi:type="dcterms:RFC4646">en</dc:language> <dc:subject>Gautama Buddha -- Fiction</dc:subject> <dc:date opf:event="publication">2001-02-01</dc:date> <dc:date opf:event="conversion">2012-11-06T12:28:23.207580+00:00</dc:date> <dc:source>http://www.gutenberg.orgfiles/2500/2500-h/2500-h.htm</dc:source> </metadata>
In selecting the field tags, we can ignore the dc: prefix, and loop through our list of fields:
// Get node values from selected field tags
foreach( $fields as $field ) {
$index[$file][$field] = $xml->getElementsByTagName( $field )->item(0)->nodeValue;}
OK, done this file, close the ZIP and continue with the next:
$zip->close();
Now all information is stored in the $index structure, so create a list and insert it in a HTML document:
// Optional, do some sorting
// or not, just use search in browser
// Create <dl> for each file
$dl = '';
foreach( $index as $file => $info ) {
$dl .= sprintf( '<dt><a href="%s">%s</a></dt><dd>%s: %s [%s]<dd>',
$file, $file, $info['creator'], $info['title'], $info['language'] );
}
// Barebone html document with <dl>
$title = 'Project Gutenberg index';
$html = <<<EOD
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>$title</title>
</head>
<body>
<h1>$title</h1>
<dl>$dl</dl>
</body>
</html>
EOD;
file_put_contents( 'index.html', $html );
?>
I hope the code came correctly through all the editing and formatting. To find the complete code, go to Github.
Practical use
I have a Dropbox folder on both my Windows PC and on my Android tablet. After downloading Gutenberg publications to Dropbox, I run the script on my PC, and the updated index will automatically be synchronized to my tablet–after all, this is Dropbox.
The script works on any set of EPUB file, but usually, they will have a more meaningful name and there will be less need for a script like this.
It is unfortunate that PG themselves cannot understand the need to increase the usability of their work product rather than people needing to “fix” their work downstream in the workflow. For years I have lamented how more consistency, transparency and minimal effort could have a substantial impact on their consumers.
hi,
what is the full form of meta-inf?
Hi,
This is documented on en.wikipedia.org/wiki/EPUB
Hi Harry,
could you please tell me how to run this script? I uploaded makeIndex.php to my server, added some epub in the same folder, but when I point my browser to makeIndex.php nothing happens…
Hi Marco,
The file makeIndex.php makes an index file, index.html
So after you run the makeIndex.php, there should be a file index.html that you can view in your browser.